
一不小心又立了一个新Flag,关于人工智能或者机器学习业界普遍认为要先学个博士才能找到好工作(这里我们不去争论学历与能力的问题),因为其中涉及的知识广度和深度都不是“30天速成”的课程所能覆盖的,甚至很多从业者也只是笑称自己是“调包侠”。笔者双非本科后就工作了,还不是计算机专业,这显得有点自不量力了。确实在学习的过程中发现高数和线性代数知识早都还给老师了。但最终我还是觉得有必要梳理一下,学不学是态度问题,学得好不好才是能力问题。
OpenAI首席科学家Ilya Sutskever在TED大会(2023年10月17日)上给出的人工智能定义:
Artificial intelligence is nothing but digital brains inside large computers.
2024年3月8日Lex Fridman Podcast中 Yann Lecun(杨立昆)开篇关于自回归的大语言模型(含GPT4,Llama 2等)无法成为超级智能的4大原因:
- 对物理世界的理解力
- 记住和提取信息的能力(持久记忆)
- 推理的能力
- 规划的能力
据笔者简单的了解,关于大语言模型其实早在一几年的时候就在机器学习(包含NLP和CV领域)达成了主攻Transformers的共识,最近Open AI(ChatGPT)的成功显然让其进入更广泛的大众视野。Transformers(见下图)是Google 于2017年发表的论文,GPT(Generative Pretrained Transformer)初期版本GPT 1和GPT 2曾经也是与Google的BERT杀得难解难分,两者都是基于Transformers,在路线上BERT使用了编码器(下图左侧上部),而GPT使用了解码器(下图右侧中间),解码器的难度其实要更高,因此Bert的风评要高于GPT 2。后来OpenAI孤注一掷、峰回路转的故事显然就不必多言了。当然OpenAI后来也被笑称为CloseAI,具体的实现细节并未公开,据说是GPT的高版本结合使用了编码器和解码器,不管如何,技术核心仍然是Transformers,更多的创新不是在技术上,而是在应用上。
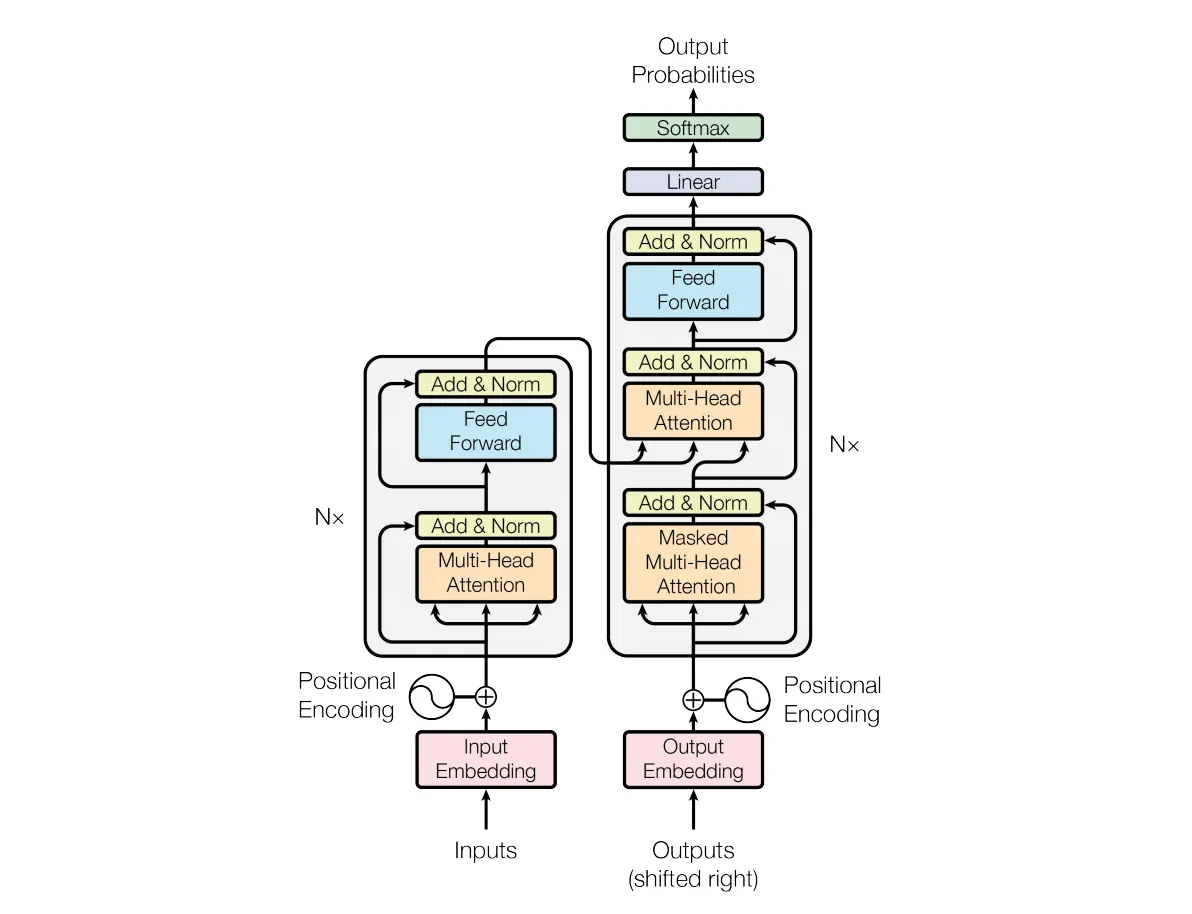
LLM和ChatGPT
- ChatGPT开发入门
- 生成式AI第一章 多媒体生成入门
- 生成式AI第二章 Transformers
- 生成式AI第三章 扩散模型Diffusion
- 生成式AI第四章 Stable Diffusion
- 生成式AI第五章 大语言模型微调
- AI大语言模型开发之初探Token和Embedding
- AI大语言模型开发之Lang Chain
- AI大语言模型开发之Fine Tuning
- …
如何学习呢?
笔者也是个新手,显然不可能整理出一个合理的大纲,我选择了一个主线,也就是《Machine Learning with PyTorch and Scikit-Learn》一书。虽然这本书很系统,但对于没有基础的人还是有很多知识需要学习,所以同时再添加一个辅线,添加一些我在学习过程中觉得欠缺的知识。
主线课程
✅第1章 赋予计算机学习数据的能力:介绍了机器学习处理各类问题任务的子领域。此外,还讨论了创建典型机器学习模型的基本步骤以及串讲了后续章节会涉及到的一些内容。
✅第2章 为分类训练简单机器学习算法:回顾机器学习起源并介绍二元感知机分类器和自适应线性神经元。本章是对模式分类基础的基本介绍,聚焦于优化算法和机器学习的相互作用。
✅第3章 使用Scikit-Learn的机器学习分类器之旅:讲解分类的基础机器学习算法,并提供了使用最流行的综合开源机器学习库scikit-learn的实例。
✅第4章 构建优秀的训练数据集 – 数据预处理:讨论如何处理未处理数据集比如缺失数据中的常见问题。还讨论了一些识别数据集中的最有效特征的方法并讲解了如何为不同类型准备变量以成为机器学习算法适合的输入。
✅第5章 通过降维压缩数据:描述在保留大部分有用和判别信息的情况下减少数据集特征数的基本技术。讨论了通过主成分分析(PCA)降维的标准方法并与监督和非线性变换技术进行了比较。
✅第6章 学习模型评估和超参数调优的最佳实践:讨论了评估预测模型表现的准则。此外还讨论了度量模型表现的指标以及调优机器学习算法的技术。
第7章 组合不同的模型进行集成学习:介绍了有效组合多种学习算法的不同概念。讲解了如何构建专家集成来克服单个学习算法的弱点,形成更精准、可靠的预测。
第8章 将机器学习应用于情感分析:讨论将文本数据变换成对机器学习算法有意义形式的步骤,来根据人们的文字预测思想。
第9章 通过回归分析预测连续目标变量:讨论对目标和响应变量进行线性关联建模在连续的尺度上预测的顶配技术。在介绍完各种线性模型后,还讨论了多项式回归和一些基于树的方法。
第10章 处理未打标签数据-聚类分析:将焦点转移到机器学习的子领域,无监督学习。我们应用了聚类算法的三类来查找共享某种程度相似性的对象分组。
第11章 从零实现多层人工神经网络:扩展了首先在第2章 为分类训练简单机器学习算法中介绍的基于梯度优化的概念,基于Python中流行的反向传播算法构建强大的多层神经网络。
第12章 使用PyTorch做并行神经网络训练:在前面章节的知识之上提供了一种更高效训练神经网络的实战指南。本章的焦点是PyTorch,一个开源Python库,让我们可以利用现代GPU的多核以及通过用户友好的灵活API提供的通用组件构建深度神经网络。
第13章 再深入一步-PyTorch的机制:继续前一章的内容,介绍PyTorch更高级的概念和功能。PyTorch是一个庞大且复杂的库,本章会带读者领略动态计算图和自动微分等概念。读者还会学习如何使用PyTorch的面向对象API实现复杂神经网络,以及PyTorch Lightning是如何帮助我们达到最佳实践和最小化样板代码的。
第14章 通过深度卷积神经网络对图像分类:介绍卷积神经网络(CNN)。CNN表示一种具体的深度神经网络架构类型,尤为适合处理图像数据集。因为比传统方法的性能更高,现在CNN广泛用于计算机视图以实现各种图像识别任务的最先进成果。通常本章读者会学习到卷积层是如何用作图像分类的强大特征提取器的。
第15章 使用循环神经网络对时序数据建模:介绍另一种用于深度学习的流行神经网络架构,尤其适合处理文件和其它类型的序列数据及时序数据。作为热身练习,本章介绍了使用循环神经网络预测电影评论的情绪。然后我们会用循环网络消化图书的信息来生成全新的文本。
第16章 Transformers-通过注意力机制改进自然语言处理:专注自然语言处理的最新趋势,讲解注意力机制如何协助对长序列的复杂关联建模。本章具体讲解影响力巨大的transformer架构以及最新的transformer模型,如BERT和GPT。
第17章 合成新数据的生成对抗网络GAN:介绍一种流行的神经网络对抗训练机制,可用于生成新的、具有真实感的图像。本章先简要介绍自动编码器,这是用于数据压缩的一种神经网络架构类型。然后向读者展示如何将自动编码器的解码器部分与另一个可分辨真实和合成图像的神经网络进行组合。通过让两个神经网络以对抗训练方法相互竞争,我们会实现一个可生成新的手写数字的生成对抗网络。
第18章 获取图结构数据中依赖的图神经网络:处理表格数据集、图像和文本以外的内容。本章介绍操作图结构数据的图神经网络,比如社交媒体网络和分子。在讲解图卷积的基础后,本章会展示一个如何实现分子数据预测模型的教程。
第19章 用于复杂环境中决策制定的强化学习:讲解机器学习一个子类,常用于训练机器人和其它自动化系统。本章会先介绍强化学习(RL)的基础,让读者熟悉智体(agent)/环境交互、强化学习的流程,以及及通过经验学习的概念。在学习了RL的主要分类后,我们会实现并训练能使用Q学习算法在网格世界中导航的一个智体,这是一种使用深度神经网络的Q学习变体。

Transformers自然语言处理
✅第1章 你好Transformer:介绍transformer及Hugging Face生态。
第2章 文本分类:主要处理情感分析的任务(一种常见的文本分类问题)并介绍了Trainer API.
第3章 解构Transformer:Transformer Anatomy, dives into the Transformer architecture in more depth, to prepare you for the chapters that follow.
第4章 多语言命名实体识别:Multilingual Named Entity Recognition, focuses on the task of identifying entities in texts in multiple languages (a token classification problem).
第5章 文本生成:Text Generation, explores the ability of transformer models to generate text, and introduces decoding strategies and metrics.
第6章 文本摘要:Summarization, digs into the complex sequence-to-sequence task of text summarization and explores the metrics used for this task.
第7章 问答:Question Answering, focuses on building a review-based question answering system and introduces retrieval with Haystack.
第8章 在生产环境让Transformer提效:Making Transformers Efficient in Production, focuses on model performance. We’ll look at the task of intent detection (a type of sequence classification problem) and explore techniques such a knowledge distillation, quantization, and pruning.
第9章 处理少标签或无记录数据:Dealing with Few to No Labels, looks at ways to improve model performance in the absence of large amounts of labeled data. We’ll build a GitHub issues tagger and explore techniques such as zero-shot classification and data augmentation.
第10章 从零开始训练Transformer:Training Transformers from Scratch, shows you how to build and train a model for autocompleting Python source code from scratch. We’ll look at dataset streaming and large-scale training, and build our own tokenizer.
第11章 未来方向: Future Directions, explores the challenges transformers face and some of the exciting new directions that research in this area is going into.
注:国内用户使用时有可能会因网络原因报
Couldn't reach huggingface.co/datasets...的错误,可设置本地代理解决该问题,如:
常见问题
-
ERROR: Could not find a version that satisfies the requirement torch (from versions: none)
检查Python版本,PyTorch经常不支持最新版的Python - Please make sure you have
sentencepieceinstalled in order to use this tokenizer.
12# 可能要重新打开编辑器pip install "transformers[sentencepiece]" - ImportError: Using the
TrainerwithPyTorchrequiresaccelerate>=0.20.1: Please runpip install transformers[torch]orpip install accelerate -U
按提示运行pip install accelerate -U,且在Colab上使用时务必Restart session
辅线课程
- 机器学习的起源
- Matplotlib库的使用和实战
- Numpy科学计算库的使用和实战
- Pandas库的使用和实战
- Scikit-learn库的使用和实战
- Pytorch库的使用和实战
- 线性代数基础
- 高等数学-学习算法/人工智能/大数据的第一步
- 探秘最炙手可热的人工智能框架TensorFlow
- 数学符号大全
- 【数学相关】希腊字母及发音
- 机器学习的经典算法
- KNN-K近邻算法
- 线性回归(linear regression)
- 逻辑回归(logistic regression)
- 前馈神经网络
- 决策树
- 随机森林
- 朴素贝叶斯
- SVM支持向量机
- EM最大期望算法
- HMM隐马尔科夫
- K-MEANS
- 集成学习







