
很多人将最近一波生成式人工智能的进展追溯到2017年发布称为transformer的模型。其最著名的应用是强大的大语言模型(LLM),如Llama和GPT-4,每天有数亿人使用。transformer已成为现代人工智能应用的核心,推动着聊天机器人、搜索系统乃至机器翻译和内容摘要等各类应用。甚至已超越了文本领域,在计算机视觉、音乐生成和蛋白质折叠等领域引起了巨大反响。本章中,我们将探讨transformer背后的核心概念及其工作原理,重点介绍其中一个最常见的应用:语言模型。
在深入了解transformer之前,我们先退一步,了解什么是语言模型。语言模型(LM)的核心是一个概率模型,它通过前面或周边的词来预测序列中的下一个词(或标记)。这样,它捕获到了语言的基本结构和模式,使其能够生成真实且连贯的文本。例如,给定句子“I began my day eating”,语言模型可能会以高概率预测下一个词为“breakfast”。
那么,transformer在这一过程中发挥什么作用呢?与使用固定大小滑动窗口或循环神经网络(RNN)的传统语言模型不同,transformer设计用于更高效、更有表现力地处理长距离依赖关系和复杂的词间关系。例如,假设您想使用语言模型总结一篇新闻文章,这篇文章可能包含数百甚至几千个词。传统的语言模型在处理长上下文时会遇到困难,因此摘要可能会遗漏文章开头的一些重要细节。而基于transformer的语言模型在这一任务上表现出色。除了高质量的生成能力外,transformer还具有其他特性,如训练的高效并行化、可扩展性和知识迁移,使其在多种任务中广受欢迎并且非常适用。这一创新的核心是自注意力机制,它使模型能够在整个序列的上下文中权衡每个词的重要性。
为建立对语言模型如何运作的直观理解,我们将使用与现有模型交互的代码示例,并在出现相关部分时进行描述。一起开干吧。
注:在英文材料中经常可以看到tranformer和transformers的表述,前者表示以自注意力机制为底层的技术,而transformers可能是指基于这一技术的各类模型,也有可能是指Hugging Face的transformers库,这个名称在营销角度非常巧妙,但也经常会让人产生误解。
本文相关代码请见GitHub仓库。
实操语言模型
在本节中,我们会加载并与现存的(预训练的)transformer模型进行互动,以获得对其工作原理的高阶理解。我们将使用2019年因文本生成能力而引发关注的GPT-2模型。尽管按今天的标准来看,GPT-2显得小而简单,但它仍然是展示这些语言模型如何运作的好例子。同样的原理也适用于自那以后发布的更大(大100多倍!)且更强的模型。
文本分词
下面开始生成基于初始输入的一些文本。例如,给定短语“it was a dark and stormy”,我们希望模型生成一些词来完善这个句子。模型不能直接接收文本作为输入;其输入必须是以数字表示的数据。为将文本输入到模型中,我们必须首先找到一种将文本序列转换为数字的方法。这个过程称为分词/标记化(tokenization),是所有自然语言处理(NLP)流程中的关键步骤。
一种简单的方法是将文本分割成单个字符,并为每个字符分配一个唯一的数字ID。这个方案对于像中文这样每个字符都包含大量信息的语言可能有用。在像英语这样的语言中,这会创建一个非常小的分词表,并且在运行推理时会有很少的未知标记(训练期间未发现的字符)。然而,这种方法需要许多标记来表示一个字符串,这对性能不利,并且会抹去文本的一些结构和含义——这对准确性是不利的。每个字符携带的信息非常少,使得模型难以学习文本的基本结构。
另一种方法是将文本按单词分割。虽然这可以让每个标记捕捉更多的含义,但它也有缺点:我们需要处理更多的未知词(例如,拼写错误、俚语等),需要处理相同词的不同形式(例如,“run”,“runs”,“running”等),并且我们可能会得到一个非常大的词表,对于像英语这样的语言来说,这个词表可轻松超过五十万个单词。现代的分词策略在这两个极端之间找到了平衡,将文本分割成既能捕获文本结构和含义又能处理未知词和相同词不同形式的词元。
通常同时出现的字符(如最常见的单词)可以分配一个代表整个单词或词组的单个标记。长或复杂的单词,以及有许多词形变化的单词,可能会被分割成多个标记,每个标记通常代表单词的一个有含义部分。没有什么“最佳”分词器;每个语言模型都有其自己的分词器。分词器之间的差异在于支持的标记数量和分词策略。
我们来看GPT-2的分词器如何处理一个句子。首先加载与GPT-2对应的分词器。然后,我们将输入文本(也称为提示词)通过分词器运行,将字符串编码为表示标记的数字。我们使用decode()方法将每个ID转换回其对应的标记,以便进行演示。
|
1 2 3 4 5 |
from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("gpt2") input_ids = tokenizer("It was a dark and stormy", return_tensors="pt").input_ids input_ids |
|
1 |
tensor([[1026, 373, 257, 3223, 290, 6388, 88]]) |
|
1 2 |
for t in input_ids[0]: print(t, "\t:", tokenizer.decode(t)) |
|
1 2 3 4 5 6 7 |
tensor(1026) : It tensor(373) : was tensor(257) : a tensor(3223) : dark tensor(290) : and tensor(6388) : storm tensor(88) : y |
可以看到,分词器将输入字符串分割成一系列标记,并为每个标记分配一个唯一的ID。大多数单词由单个标记表示,但“stormy”被表示为两个标记:一个是“ storm”(包括单词前的空格),另一个是后缀“y”。这使得模型能够学习“stormy”与“storm”有关,后缀“y”通常用于将名词变成形容词。GPT-2的词表大约50,000个标记,分词器可以高效地表示几乎所有输入文本,平均每个单词大约1.3个标记。
注:尽管我们经常谈论训练分词器,它与训练模型没有关系。模型训练本质上是随机的(非确定性的),而训练分词器使用的是统计过程,识别出哪些子词在给定数据集中是最合适的选择。如何选择子词是分词算法的设计决策。因此,标记化训练是确定性的。我们不会深入探讨不同的分词策略,但一些最流行的分词方法包括在GPT-2中使用的字节级BPE、WordPiece和SentencePiece。
预测概率
GPT-2按因果语言模型(也称为自回归模型)训练,这表示它被训练用来在给定前面的标记后预测序列中的下一个标记。transformers库提供了高级工具,让我们能够快速使用这样的模型生成文本或执行其他任务。通过直接检查语言建模任务中的预测,可以帮助我们理解模型如何做出预测。首先来加载模型。
|
1 2 3 |
from transformers import AutoModelForCausalLM gpt2 = AutoModelForCausalLM.from_pretrained("gpt2") |
注:请注意
AutoTokenizer和AutoModelForCausalLM的使用。transformers库支持几百个模型及相应的分词器。为避免记住每个分词器和模型类的名称,我们使用AutoTokenizer和AutoModelFor。对于自动模型,我们需要指定使用模型的任务,例如分类(
AutoModelForSequenceClassification)或目标检测(AutoModelForObjectDetection)。对于GPT-2,我们将使用与因果语言建模任务相对应的类。使用自动类时,transformers会根据模型的配置选择适用的默认类。例如,其背后使用GPT2Tokenizer和GPT2LMHeadModel。
如果我们将上一节中的分词/词法单元句子输入模型,会得到每个输入字符串标记对应的50,257个值的结果:
|
1 2 |
outputs = gpt2(input_ids) outputs.logits.shape # An output for each input token |
|
1 |
torch.Size([1, 7, 50257]) |
输出的第一个维度是批次的数量(1是因为我们只通过模型运行了一个序列)。第二个维度是序列长度,即输入序列中的标记数量(本例中是7)。第三个维度是词汇量大小。我们为原始序列中的每个标记得到大约5万多个数字的列表。这些是模型的原始输出,或称logits,对应于词表中的标记。对于每个输入标记,模型预测词表中每个标记在该点之后延续序列的可能性。以我们的示例句子为例,模型将为“It”,“It was”,“It was a”等预测logits。较高的logits值意味着模型认为相应的标记更可能是序列的延续。下表显示了输入序列、最可能的标记ID及其对应的标记。
Logits是模型的原始输出(如一串数字[0.1, 0.2, 0.01, …])。我们可以使用logits来选择最可能延续序列的标记。然而,我们也可以将logits转换为概率,下面会看到。
| 输入序列 | 最可能的下一个标记的ID | 对应的token |
|---|---|---|
| It | 318 | is |
| It was | 257 | a |
| It was a | 845 | very |
| It was a dark | 1755 | night |
| It was a dark and | 4692 | cold |
| It was a dark and storm | 88 | y |
| It was a dark and stormy | 1755 | (let’s figure this one) |
我们来关注整个输入句子的logits,并看看如何预测句子的下一个单词。我们可以使用argmax()方法找到具有最高值的标记索引:
|
1 2 |
final_logits = gpt2(input_ids).logits[0, -1] # The last set of logits final_logits.argmax() # The position of the maximum |
|
1 |
tensor(1755) |
1755 对应于模型认为最有可能接输入字符串 “
It was a dark and stormy” 的标记ID。解码这个标记,我们可以看到这个模型还是清楚一些故事套路的:|
1 |
tokenizer.decode(final_logits.argmax()) |
|
1 |
' night' |
所以” night”是最可能的词元。考虑输入的语句,这是讲得通的。模型学会了使用一种叫做自注意力的算法来关注其他词元,这是transformer的基本构件。直观地说,自注意力让模型能识别每个词元对短语含义的贡献有多大。
注:transformer模型包含了许多这样的注意力层,每一层都专注于输入的某一方面。与启发式系统相反,这些方面或特征是在训练过程中学习到的,而非事先指定的。
下面我们通过选择前10个值来看看其他候选词元:
|
1 2 3 4 5 |
import torch top10_logits = torch.topk(final_logits, 10) for index in top10_logits.indices: print(tokenizer.decode(index)) |
|
1 2 3 4 5 6 7 8 9 10 |
night day evening morning afternoon summer time winter weekend , |
需要将logits转换成概率值,以查看模型对每次预测的置信度。我们会通过将每个值与所有其他预测值进行比较,并进行归一化,以使所有数字加起来等于1。这正是softmax()运算的任务。以下代码使用softmax()打印出模型所得可能性最高的前10个词汇及其相关概率:
|
1 2 3 |
top10 = torch.topk(final_logits.softmax(dim=0), 10) for value, index in zip(top10.values, top10.indices): print(f"{tokenizer.decode(index):<10} {value.item():.2%}") |
|
1 2 3 4 5 6 7 8 9 10 |
night 46.18% day 23.46% evening 5.87% morning 4.42% afternoon 4.11% summer 1.34% time 1.33% winter 1.22% weekend 0.39% , 0.38% |
生成文本
|
1 2 3 4 5 6 |
output_ids = gpt2.generate(input_ids, max_new_tokens=20) decoded_text = tokenizer.decode(output_ids[0]) print("Input IDs", input_ids[0]) print("Output IDs", output_ids) print(f"Generated text: {decoded_text}") |
|
1 2 3 4 5 6 |
Input IDs tensor([1026, 373, 257, 3223, 290, 6388, 88]) Output IDs tensor([ 1026, 373, 257, 3223, 290, 6388, 88, 1755, 13, 383, 2344, 373, 19280, 11, 290, 262, 15114, 547, 7463, 13, 383, 2344, 373, 19280, 11, 290, 262]) Generated text: It was a dark and stormy night. The wind was blowing, and the clouds were falling. The wind was blowing, and the |
在上一节中运行
gpt2()的方法时,它返回了词汇表(50257)中每个标记的logits列表。然后,我们需要计算概率并选择最可能的标记。generate()抽象了这个逻辑。它进行多次前向传播,反复预测下一个标记,并将其追加到输入序列中。generate()为我们提供了最终序列的token ID,包括输入和新标记。然后,我们可以用 tokenizer 的decode()方法将其转换回文本。
执行生成有许多种策略。我们刚才选择最大可能性的标记,被称为贪婪解码(greedy decoding)。尽管这种方法直截了当,但有时可能导致次优的结果,特别是在生成较长文本序列时。贪婪解码存在问题,因为它不考虑整个句子的总概率,只关注紧接着的下一个词。例如,给定起始词 Sky和下一个词的选择 blue 和 rockets,贪婪解码可能会偏向 Sky blue,因为blue初看起来更可能紧跟 Sky。然而,这种方法会忽视更连贯和可能的整体序列,如Sky rockets soar。因此,贪婪解码有时会错过最可能的整体序列,导致文本生成的效果不理想。
与一次一个token不同,如 Beam Search(束集搜索)这样的技术,会探索序列的多种可能延续,并返回最可能的延续序列。它在生成过程中保持最有可能的 num_beams假设,并选择最有可能的那个。
|
1 2 3 4 5 6 7 |
beam_output = gpt2.generate( input_ids, num_beams=5, max_new_tokens=30, ) print(tokenizer.decode(beam_output[0], skip_special_tokens=True)) |
|
1 2 3 4 5 |
It was a dark and stormy night. "It was dark and stormy," he said. "It was dark and stormy," he said. |
可以看到,输出中存在相同序列的多次重复。有一些参数可用于控制执行更好的生成。来看两个例子:
repetition_penalty:对已生成的词元进行多大程度的惩罚,避免重复。比较好的默认值是1.2。bad_words_ids:不应生成的词元列表(例如防止生成冒犯性的词汇)。
下面看惩罚重复所得到的效果:
|
1 2 3 4 5 6 7 8 |
beam_output = gpt2.generate( input_ids, num_beams=5, repetition_penalty=1.2, max_new_tokens=38, ) print(tokenizer.decode(beam_output[0], skip_special_tokens=True)) |
|
1 2 3 4 5 |
It was a dark and stormy night. "There was a lot of rain," he said. "It was very cold." He said he saw a man with a gun in his hand. |
效果好很多。该使用哪种生成策略呢?就像机器学习中常说的……这取决于具体情况。当文本的期望长度比较可预测时,束集搜索(beam search)效果较好。它适用于摘要或翻译等任务,但不适用于开放式生成,因为输出长度可能有较大变化,导致重复。尽管我们可以限制模型避免重复,但这样做也可能导致性能下降。还要注意,束集搜索比贪婪搜索(greedy search)要慢,因为它需要同时对多个束进行推理,这对大型模型来说可能是个问题。
在使用贪婪搜索和束集搜索生成文本时,我们提升模型生成高概率的下一个词的分布。有趣的是,高质量的人类语言并不遵循类似的分布。人类文本往往更不可预测。关于这一反直觉现象的优秀论文有《神经文本退化的奇特案例》。作者推测人类语言不喜欢可预测的词语——人们会避免陈述显而易见的内容。论文提出了一种称为核采样(nucleus sampling)的方法。
采样时,我们通过从下一个词的概率分布中采样来选择下一个词。这意味着采样是一个不确定性的生成过程。如下一个词可能是night(60%)、day(35%)和apple(5%),那么与其选择night(使用贪婪搜索),我们会从分布中采样。换句话说,即使apple是一个低概率的词,有5%的几率被选择,尽管它可能产生不合逻辑的生成内容。采样避免了生成重复文本,因此可以产生更多样化的内容。采样在transformer模型中通过 do_sample 参数来完成。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from transformers import set_seed # Setting the seed ensures we get the same results every time we run this code set_seed(70) sampling_output = gpt2.generate( input_ids, do_sample=True, max_length=34, top_k=0, # We'll come back to this parameter ) print(tokenizer.decode(sampling_output[0], skip_special_tokens=True)) |
|
1 |
It was a dark and stormy day until it broke down the big canvas on my sleep station, making me money dilapidated, and, with a big soothing mug |
我们可以在采样之前操控概率分布,通过temperature参数使其变得“更陡峭”或“更平缓”。temperature高于1会增加分布的随机性,这样可以鼓励生成可能性较低的词。temperature在0和1之间会减少随机性,增加可能性较高词的概率,避免过于出乎意料的预测。temperature为0会将所有概率集中到最可能的下一个词,相当于贪婪解码。对比以下示例中temperature参数对生成文本的影响。
|
1 2 3 4 5 6 7 8 9 |
sampling_output = gpt2.generate( input_ids, do_sample=True, temperature=0.4, max_length=40, top_k=0, ) print(tokenizer.decode(sampling_output[0], skip_special_tokens=True)) |
|
1 |
It was a dark and stormy night, and I was alone. I was in the middle of the night, and I was suddenly awakened bygoodness, and I was thinking of the old man |
|
1 2 3 4 5 6 7 8 9 |
sampling_output = gpt2.generate( input_ids, do_sample=True, temperature=0.001, max_length=40, top_k=0, ) print(tokenizer.decode(sampling_output[0], skip_special_tokens=True)) |
|
1 |
It was a dark and stormy night. The wind was blowing, and the clouds were falling. The wind was blowing, and the clouds were falling. The wind was blowing, and the clouds were |
|
1 2 3 4 5 6 7 8 9 |
sampling_output = gpt2.generate( input_ids, do_sample=True, temperature=3.0, max_length=40, top_k=0, ) print(tokenizer.decode(sampling_output[0], skip_special_tokens=True)) |
|
1 |
It was a dark and stormyfleet verteutorial took possession contingt containing Carol Rhino soils titsfastKEY 07 Deaths od paradeCONT WEEK Barclays Reviskish6 EdwingarPosition serv blat Imperial licenseium Bot |
第一条测试比第二条连贯得多。第二条测试使用了非常低的temperature,因此文本重复(类似于贪婪解码)。最后,第三个样本temperature极高,生成了无意义的文本。
你可能注意到有一个参数是top_k。是什么呢?Top-K采样是一种简单的采样方法,其中只考虑K个最有可能的后续词。例如,使用top_k=5,生成方法会首先筛选出最有可能的五个词,并重新分配概率使其总和为一。
|
1 2 3 4 5 6 7 8 |
sampling_output = gpt2.generate( input_ids, do_sample=True, max_length=40, top_k=10, ) print(tokenizer.decode(sampling_output[0], skip_special_tokens=True)) |
|
1 2 3 |
It was a dark and stormy night and there were some things we didn't understand. I didn't understand the nature of the problem. I was afraid and scared." In response to the |
嗯……还可以更好。Top-K采样的一个问题是实际中相关候选词的数量可能会有很大差异。如果定义top_k=5,有些分布仍然会包含概率非常低的词,而其他分布则仅包含高概率词。
我们介绍的最后一种生成策略是Top-p采样(也称为核采样)。与采样最高概率的K个词不同,我们使用所有累计概率超过给定值的最可能词。如果我们使用top_p=0.94,首先会筛选出累计概率达到0.94或更高的词,然后重新分配概率并进行常规采样。下面看看实际效果。
|
1 2 3 4 5 6 7 8 9 |
sampling_output = gpt2.generate( input_ids, do_sample=True, max_length=40, top_p=0.94, top_k=0, ) print(tokenizer.decode(sampling_output[0], skip_special_tokens=True)) |
|
1 |
It was a dark and stormy night from 7PM. Tony attended the Rangers game with his boys. He overheard them singing. He recorded a video with Jasper in the booth. He rented an empty |
Top-K和Top-p都是实践中常用的生成方法。它们甚至可以结合起来过滤掉低概率词,同时提供更多的生成控制。使用随机生成方法的问题是生成的文本不一定连贯。
我们已经看到了三种不同的生成方法:贪婪搜索、束集搜索解码和采样(通过temperature、Top-K和Top-p进一步控制)。这类方法很多!如果你想进一步测试生成方法,以下是一些建议:
- 尝试不同的参数值。增加束的数量会如何影响生成质量?减少或增加
top_p值会发生什么? - 一种减少束集搜索中重复的方法是引入n-gram(n个词的序列)惩罚。可以通过
no_repeat_ngram_size配置,避免重复相同的n-gram。例如,使用no_repeat_ngram_size=4,生成的文本就不会包含完全相同的四个连续词。 - 一种较新的方法,反差搜索,可以生成长且连贯的内容,同时避免重复。这是通过考虑模型预测的概率和上下文的相似性来实现的。可以通过
penalty_alpha和top_k控制。有关反差搜索可阅读Generating Human-level Text with Contrastive Search一文。
如果这听起来太经验主义,那是因为确实是这么回事。生成式是一个活跃的研究领域,新论文不断提出不同的方案,如更复杂的过滤方法。我们将在最后一章简要讨论这些内容。没有一种方法适用于所有模型,所以对不同的技术做实验很重要。
零样本泛化
生成式语言是transformer模型的一个有趣而令人振奋的应用,但撰写关于独角兽的伪造文章并不是其如此受欢迎的原因。为了很好地预测后一个词,这些模型必须学到相当多的现实世界的知识。我们可以利用这一点来执行各种任务。例如,无需训练一个专门用于翻译的模型,只需用一个足够强大的语言模型来输入一个提示词,像这样:
|
1 2 3 |
Translate the following sentence from English to French: Input: The cat sat on the mat. Translation: |
我在GitHub Copilot中实时输入了这一示例,它贴心地建议将“Le chat était assis sur le tapis”作为以上提示词的延续——这是语言模型可以执行未明确训练任务的完美例子。模型越强大,它在无需额外训练的情况下可以执行的任务就越多。这种灵活性使得transformer模型非常强大,并在近年来变得广受欢迎。
为能亲身体验,我们使用GPT-2作为分类模型。具体来说,我们会对电影评论进行正面或负面的分类——这是NLP领域的经典基准任务。为增加趣味性,我们使用零样本的方式,也就是我们不会向模型提供任何标记数据。而是向模型提供评论文本,让其预测情感。来看看它的表现。
我们将评论插入一个提示词模板,为模型提供上下文,并帮助它理解我们的要求。将提示词输入模型后,查看它对后一个词的预测,看看哪个词概率更高:“positive”还是“negative”?为此,我们需要找出这些词的相应ID。
|
1 2 3 |
# Check the token IDs for the words ' positive' and ' negative' # (note the space before the words) tokenizer.encode(" positive"), tokenizer.encode(" negative") |
|
1 |
([3967], [4633]) |
有了ID之后,就可以使用模型进行推理,查看哪个词具有更高的概率:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
def score(review): """Predict whether it is positive or negative This function predicts whether a review is positive or negative using a bit of clever prompting. It looks at the logits for the tokens ' positive' and ' negative' (note the space before the words), and returns the label with the highest score. """ prompt = f"""Question: Is the following review positive or negative about the movie? Review: {review} Answer:""" input_ids = tokenizer(prompt, return_tensors="pt").input_ids # 对提示词进行分词 final_logits = gpt2(input_ids).logits[0, -1] # 从词汇中获取每个词元的logit,注意我们使用的是gpt2()而不是gpt2.generate(),因为前者返回词中的每个分词的logit,而后者仅返回所选定的分词 if final_logits[3967] > final_logits[4633]: # 检测正向分词的logit是否大于负向分词的logit print("Positive") else: print("Negative") |
可以对几个假评论使用zero-shot分类器进行尝试:
|
1 |
score("This movie was terrible!") |
|
1 |
Negative |
|
1 |
score("That was a delight to watch, 10/10 would recommend :)") |
|
1 |
Positive |
|
1 |
score("A complex yet wonderful film about the depravity of man") |
|
1 |
Positive |
在补充材料中,有一个已打标记的评论数据集和用于评估这种零样本方法准确性的代码。尝试调整提示词模板以提高模型的性能。看看还能想到其他可以使用类似方法执行的任务吗?
最近模型的零样本能力大大改变了游戏规则。随着模型的改进,它们可以开箱即用地执行更多任务,使其更易于使用,并减少了每个任务需要专用模型的需求。
少样本泛化
虽然有先进的ChatGPT以及对外界完美提示词的追求,零样本泛化(或提示词调优)并不是让强大的语言模型执行各类任务的唯一路径。
零样本泛化是少样本(few-shot )泛化技术的极端应用,在少样本泛化中,我们向语言模型提供一些希望它执行的任务的示例,然后让其提供类似的答案。我们不是在训练模型,而是通过展示一些示例来影响生成的内容,增加生成文本遵循我们的提示词结构和模式的概率。
来看一个例子。提供示例之外,提供一段简短的描述,例如“Translate English to French”,也有助于生成更高质量的内容。这次,我们使用一个更强大的模型:GPT-Neo 1.3B。GPT-Neo是由非营利研究实验室EleutherAI开发的一系列transformer模型。这些模型在许多任务中表现优于GPT-2,并且在少样本学习方面表现更好。我们使用13亿参数的变体,虽然在今天看来不算大,但它依然相当强大,是GPT-2(仅有1.24亿参数)的十倍。
|
1 |
model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-neo-1.3B") |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
prompt = """\ Translate English to Spanish: English: I do not speak Spanish. Spanish: No hablo español. English: See you later! Spanish: ¡Hasta luego! English: Where is a good restaurant? Spanish: ¿Dónde hay un buen restaurante? English: What rooms do you have available? Spanish: ¿Qué habitaciones tiene disponibles? English: I like soccer Spanish:""" inputs = tokenizer(prompt, return_tensors="pt").input_ids output = model.generate( inputs, do_sample=False, max_new_tokens=10, ) print(tokenizer.decode(output[0], skip_special_tokens=True)) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Translate English to Spanish: English: I do not speak Spanish. Spanish: No hablo español. English: See you later! Spanish: ¡Hasta luego! English: Where is a good restaurant? Spanish: ¿Dónde hay un buen restaurante? English: What rooms do you have available? Spanish: ¿Qué habitaciones tiene disponibles? English: I like soccer Spanish: Me gusta el fútbol |
我们描述了要实现的任务,并提供了四个示例设置模型的上下文。因此,这是一个4-shot泛化任务。然后,我们要求模型生成更多文本以遵循模式并提供所需的翻译。以下是一些可以探索的想法:
- 更少的示例是否可以?
- 没有任务描述是否可行?
- 其他任务如何?
- 在这一情况下,GPT-2的表现如何?
注:由于GPT-2的大小和训练过程,它在少样本任务上表现不是很好,在零样本泛化上甚至更差。我们如何在之前的例子中使用它进行情感分类呢?其实做了一点小手脚:我们没有查看模型生成的文本,只是检查了“Positive”的概率是否大于“Negative”的概率。理解模型的底层工作原理,即使是小模型,也能解锁强大的应用。要思考你的问题,不要害怕探索。
GPT-2是一个基础模型的例子。以GPT-2为风格的一些底座模型具有在推理时使用的零样本和少样本能力。另一种方式是模型微调:我们在基础模型之上继续在特定的领域或任务数据上训练。通常很少需要世界上最强大的模型展示的极端泛化能力;如果只要解决一个特定任务,更便宜且更好的是微调并部署一个专门用于单一任务的小模型。同样重要的是要注意基础模型不是对话式的;尽管可以编写一个非常好的提示词来使用基础模型创建一个聊天机器人,但通常更方便的是使用对话数据微调基础模型,从而提高模型的对话能力。在第五章中会进行实践。
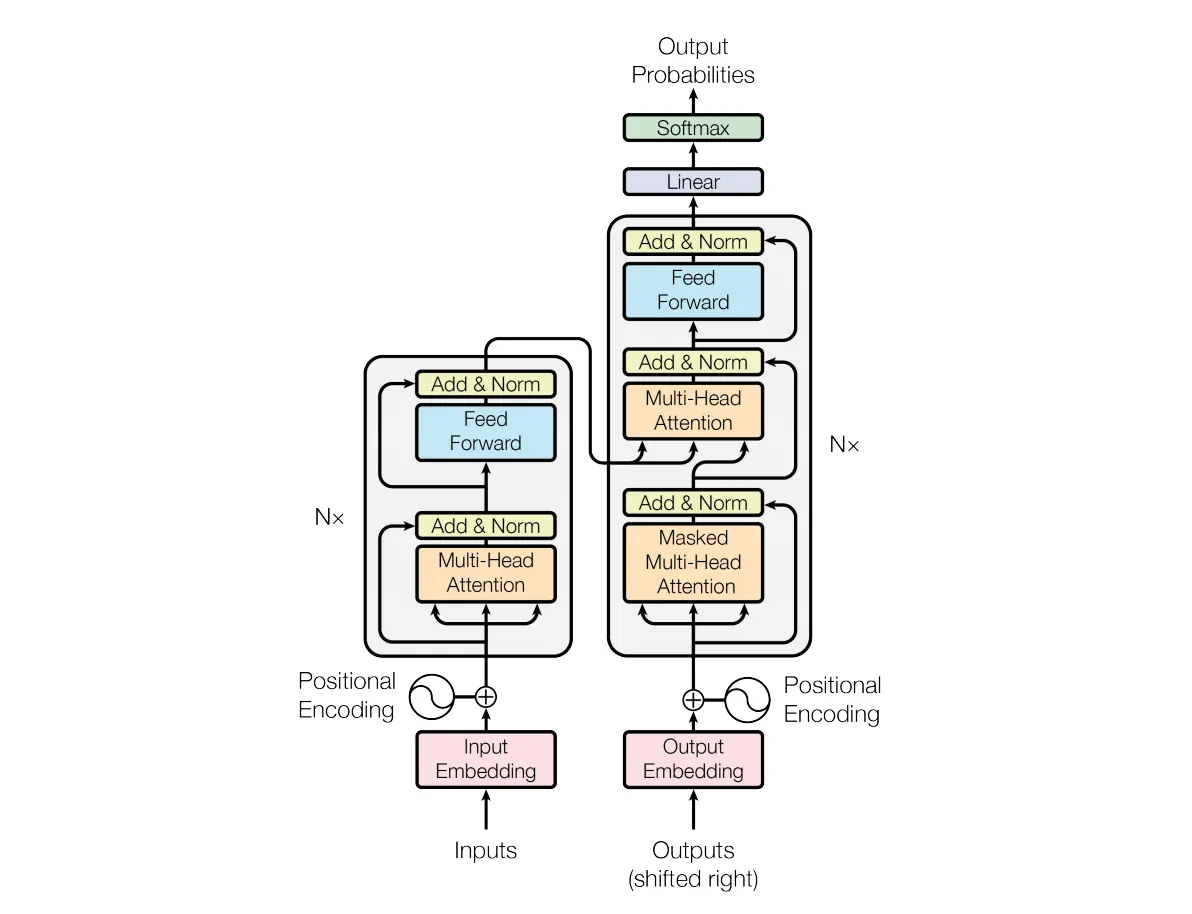
Transformer解构
在简单实践语言模型之后,我们准备介绍基于transformer的语言生成模型的架构图。涉及到的高阶组件有:
- 分词:输入文本被分解为单个token(可以是单词和子词)。每个词元都有一个对应的ID,用于索引词嵌入。
- 输入词嵌入:token以称为嵌入的向量进行表示。这些嵌入为数值形式,捕获每个token的语义。可以将向量视为数字列表,每个数字对应token含义的特定方面。在训练过程中,模型学习如何将每个token映射到对应的嵌入。无论token在输入序列中的位置如何,嵌入总是相同的。
- 位置编码:transformer模型没有顺序的概念,因此我们需要用位置信息丰富词嵌入。通过将位置编码添加到词嵌入中来实现。位置编码是一组向量,编码了输入序列中每个token的位置。使得模型能够根据序列中的位置区分标记,这很有用,因为同一个token出现在不同位置可以有不同的含义。
- Transformer块:transformer模型的核心是transformer块。transformer的强大之处在于堆叠多个块,使模型能够学习输入token之间越来越复杂和抽象的关系。它由两个主要组件组成:
- 自注意义力机制:这种机制允许模型在整个序列的上下文中权衡每个token的重要性。它帮助模型理解输入中不同token之间的关系。自注意力机制是transformer处理长程依赖和复杂词语关系的关键,可生成连贯且语境恰当的文本。
- 前馈神经网络:自注意力输出通过前馈神经网络进一步细化输入序列的表示。
- 上下文嵌入:transformer块的输出是一组上下文嵌入,捕获输入序列中token之间的关系。与每个token固定的输入嵌入不同,上下文嵌入在transformer模型的每一层中根据token之间的关系进行更新。
- 预测:一个额外的层将最终表示处理为任务相关的最终输出。对于文本生成,这涉及一个线性层将上下文嵌入映射到词空间,随后进行softmax运算以预测序列中的下一个token。

图2-1:基于transformer的模型的架构
当然,这只是对transformer架构的简化描述。深入研究自注意力机制的工作原理或transformer块的内部机制暂不在我们的讨论范围。但理解transformer模型的顶层架构有助于掌握这些模型的工作原理以及将其应用于各种任务。这种架构使transformer在各种任务和领域中取得了前所未有的表现,你会发现它们不断出现——不仅是在本系列文章,而是在整个学科中。
Transformer模型家族
序列到序列的任务
在本章的开头,我们使用GPT-2进行了自回归文本生成实验。GPT-2是基于解码器的transformer示例,它具有一组transformer块,用于处理输入序列。这是当今流行的方式,但原始的transformer论文《Attention Is All You Need》中使用了一种更复杂的架构,称为编码器-解码器架构,这种架构至今仍在广泛使用。
transformer论文专注于机器翻译这一序列到序列的任务。当时,机器翻译的最佳结果是通过循环神经网络(RNN)实现的,例如LSTM和GRU(读者如果不熟悉,不必担心)。该论文通过专注于注意力方法展示了更好的结果,并表达了其可扩展性和训练更容易。这些因素——出色的表现、稳定的训练和易于扩展——是transformer取得成功并被应用于多种任务的原因,下一节将更深入地探讨这些方面。
在编码器-解码器模型中,就像论文中描述的原始transformer模型,一组transformer块(称为编码器)将输入序列处理成一组丰富的表示,然后将其传递给另一组transformer块(称为解码器),解码它们为输出序列。这种将一个序列转换为另一个序列的方法称为序列到序列或seq2seq,适用于翻译、摘要或问答等任务。
例如,将一段英文句子喂给翻译模型的编码器,生成一个捕获输入含义的嵌入。然后,解码器使用这个嵌入生成对应的法语句子。生成过程在解码器中按token逐一进行,在本章早些时候生成序列时有演示。然而,对每个后续token的预测不仅受到正在生成的序列中前一个token的影响,还受到来自编码器的输出的影响。
将编码器端的输出合并到解码器堆栈中的机制称为交叉注意力。它类似于自注意力,不同之处在于输入中的每个token(解码器正在处理的序列)关注的是来自编码器的上下文,而不是其序列中的其他token。交叉注意力层与自注意力交错,让解码器能够使用其序列中的上下文和来自编码器的信息。
在transformer论文发表后,现有的序列到序列模型,如Marian NMT,将这些技术作为其架构的核心部分进行了整合。使用这些思想开发了新的模型。其中一个值得关注的是BART(“Bidirectional and Auto-Regressive Transformers”的缩写)。在预训练期间,BART会破坏输入序列,并尝试在解码器输出中重建。之后,BART会针对其他生成任务(如翻译或摘要)进行微调,利用预训练期间获得的丰富序列表示。顺便说一下,输入破坏是扩散模型背后的关键思想之一,我们将在第三章中讲到。
另一个值得注意的序列到序列模型是T5。T5以通用的方式处理多种NLP任务,通过将60种任务表述为文本到文本的转换。不同任务不需要自定义层或代码,训练使用相同的超参数,模型从多样化的数据集中学习。
我们刚刚讨论了编码器-解码器和单解码器架构。常见的问题是,为什么像翻译这样的任务需要编码器-解码器模型,而诸如GPT-2的单解码器模型也能表现良好的结果。编码器-解码器模型旨在将整个输入序列翻译为输出序列,使其极其适合翻译任务。而单解码器模型专注于预测序列中的下一个token。最初,像GPT-2这样的单解码器模型在零样本学习场景中的能力不如更先进的模型如GPT-3,但这不仅仅是因为缺少编码器。像GPT-3这样的高级模型在零样本能力上的提升源自更大的训练数据、改进的训练技术和更大的模型规模。尽管seq2seq模型中的编码器在理解输入序列的完整上下文中发挥着关键作用,但单解码器模型的进步使它们更加有效和多样化,即使对于传统上依赖seq2seq模型的任务也是如此。
编码器模型
可以看到,原始的transformer模型基于编码器-解码器架构,这种架构在BART或T5等模型中得到了进一步探索。此外,编码器或解码器可以单独训练和使用,从而产生不同的transformer家族。本章的前几节探讨了单解码器或自回归模型。这些模型专门用于使用我们描述的技术生成文本,并且表现令人印象深刻,如ChatGPT、Claude、Llama或Falcon。
另一方面,编码器模型专门用于从文本序列中获得丰富的表示,可用于分类等任务,或为检索系统准备大量文档的语义嵌入(通常是几百个数字的向量)。最著名的transformer编码器模型可能是BERT,它引入了掩码语言模型目标,后来由BART进一步探索。
因果语言模型预测给定前一个标记的下一个token——如GPT-2。模型只能关注给定标记左侧的上下文。在编码器模型中使用的不同方法称为掩码语言模型(MLM)。掩码语言模型在著名的BERT论文中提出,它对模型进行预训练以学习“完形填空”。给定一个输入文本,我们随机掩盖一些标记,模型必须预测隐藏的token。与因果语言模型不同,MLM使用掩码标记左右两侧的序列,这就是BERT名称中表示“双向”的B。它有助于创建给定文本的表现。这些模型在底层使用transformer架构的编码器部分。
|
1 2 3 4 |
from transformers import pipeline fill_masker = pipeline(model="bert-base-uncased") fill_masker("The [MASK] is made of milk.") |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
[{'score': 0.19546717405319214, 'token': 9841, 'token_str': 'dish', 'sequence': 'the dish is made of milk.'}, {'score': 0.1290748566389084, 'token': 8808, 'token_str': 'cheese', 'sequence': 'the cheese is made of milk.'}, {'score': 0.10590700060129166, 'token': 6501, 'token_str': 'milk', 'sequence': 'the milk is made of milk.'}, {'score': 0.041120897978544235, 'token': 4392, 'token_str': 'drink', 'sequence': 'the drink is made of milk.'}, {'score': 0.03712378069758415, 'token': 7852, 'token_str': 'bread', 'sequence': 'the bread is made of milk.'}] |
底层发生了什么?编码器接收输入序列并为每个标记生成上下文表示。这种表示是一个数值向量,捕获了标记在整个序列中的含义。编码器通常后接一个特定任务层,该层使用这些表示来执行分类、问答或掩码语言建模等任务。编码器被训练生成重度理解所需的表示。
在单编码器、单解码器和编码器-解码器模型之中,已出现大量新的开源和闭源语言模型,如GPT-4、Mistral、Falcon、Llama 2、Qwen、Yi、Claude、Bloom、PaLM等。杨立昆(LeCun)在Twitter上发布了一张有趣的族谱图,摘自一篇研究论文,展示了截至2024年transformer在NLP领域中的丰富且富有成果的影响。

预训练的强大
Transformer的核心洞察
现有模型都非常强大。在前几节中,我们探讨了使用GPT-2和GPT-NeoX生成文本并进行零样本分类。transformer模型在许多其他语言任务中也表现出最佳性能,如文本分类、机器翻译和基于输入文本的问答。为什么transformer能这么好?
第一点是注意力机制的使用,正如本章引文中所提到的。以前的NLP方法,如循环神经网络,难以处理长句子。注意力机制使得transformer模型能关注长序列并学习长程关系。也就是说,transformer可以估计某些标记对其他标记的相关性。
第二个关键点是其可扩展性。transformer架构具有优化的并行化实现,研究表明这些模型可以扩展以处理高复杂度和大规模数据集。虽然最初是为文本数据设计的,但transformer架构足够灵活,可支持不同的数据类型并处理不规则的输入。
第三个关键点是预训练和微调的能力。传统的任务方法,如电影评论分类,受到标注数据可用性的限制。模型将从头开始在大量标注示例上训练,尝试直接从输入文本预测标签。这种方法通常称为监督学习。然而,它有一个显著的缺点:需要大量标注数据才能有效训练。这是一个问题,因为标注数据昂贵且耗时。在许多领域甚至没有可用的数据。
为解决这个问题,研究人员开始寻找一种方法,在现有数据上预训练模型,然后为特定任务进行微调(或调整)。这种方法称为迁移学习,是许多领域(如自然语言处理和计算机视觉)现代机器学习的基础。NLP的初期工作集中在寻找特定领域的语料库进行语言模型预训练,但ULMFiT等论文表明,即使在维基百科等通用文本上进行预训练,也能在微调下游任务(如情感分析或问答)时取得令人非常好的结果。这为transformer的崛起奠定了基础,事实证明transformer非常适合学习丰富的语言表示。
预训练的理念是,在一个大型未标注数据集上训练模型,然后针对新目标任务进行微调,这样所需的标注数据就少得多。在转向NLP之前,迁移学习已经在构成现代计算机视觉骨干的卷积神经网络中取得了巨大成功。在这种情况下,首先在一个包含大量标注图像的分类任务上训练一个大型模型。通过这个过程,模型学习到可以在不同但相关的问题上利用通用特征。例如,我们可以在成千上万个类别上预训练一个模型,然后微调它来分类图片是否为热狗。
对于transformer,更进一步地采用了自监督预训练。我们可以在大型未标注文本数据上预训练一个模型。怎么做呢?思考一下因果模型如GPT。模型预测下一个词是什么。那么,我们不需要任何标签来获取训练数据。给定一个文本语料库,我们可以在序列后屏蔽标记,并训练模型学习预测它们。就像在计算机视觉案例中一样,预训练为模型提供了文本的有意义表示。然后我们可以微调模型来执行其他任务,如生成自己推文风格的文本或特定领域的文本(例如,公司对话)。由于模型已经学习了语言表示,微调所需的数据比从头开始训练少得多。
对于许多任务,输入的丰富表示比能够预测下一个标记更重要。例如,如果你想微调一个模型来预测电影评论的情感,掩码语言模型会更强大。像GPT-2这样的模型旨在优化文本生成,而不是构建强大的文本表示。另一方面,像BERT这样的模型非常适合这个任务。如前所述,编码器模型的最后一层输出的是输入序列的稠密表示,称为嵌入。然后可以通过在编码器上添加一个小型简单的网络并微调模型来完成特定任务。例如,我们可以在BERT编码器输出的基础上添加一个简单的线性层,以预测文档的情感。可以采用这种方法来处理各种任务:
- 标记分类:识别句子中的每个实体,如人、地点或组织。
- 抽取式问答:给定一个段落,回答一个具体问题并从输入中提取答案。
- 语义搜索:编码器生成的特征可以用于构建搜索系统。给定一个包含百篇文档的数据库,我们可以计算每个文档的嵌入。然后,可以在推理时将输入嵌入与文档的嵌入进行比较,从而识别数据库中最相似的文档。
注:此处过度简化了语义搜索的原理,但在后面的挑战小节会有机会使用语义搜索构建一个简单的搜索系统。 - 以及许多其他任务,包括文本相似性、异常检测、命名实体链接、推荐系统和文档分类。
|
1 2 3 4 |
from transformers import pipeline classifier = pipeline(model="distilbert-base-uncased-finetuned-sst-2-english") classifier("This movie is disgustingly good !") |
|
1 |
[{'label': 'POSITIVE', 'score': 0.9998536109924316}] |
这个分类模型可以分析评论,并执行零样本分类一节中的相同操作。本章的挑战小节展示了如何评估分类模型并比较零样本设置与微调模型之间的差异。
Transformer回顾
我们讨论了三种架构类型:
- 基于编码器的架构,如BERT、DistilBERT和RoBERTa,适合需要理解整个输入的任务。这些模型输出捕获输入序列含义的上下文嵌入。我们可以在这些嵌入的基础上添加一个小型网络,进行训练完成依赖语义信息的新特定任务(如识别文本中的实体或对序列进行分类)。
注:DistilBERT是一个较小的模型,保留了原BERT 95%的功能,但参数量要少40%。RoBERTa是一个基于BERT的强大模型,采用了不同的超参数进行训练,规模更大。 - 基于解码器的架构,如GPT-2、Falcon和Llama,适合生成新文本。
- 编码器-解码器架构,或seq2seq,如BART和T5,适合基于给定输入生成新句子的任务,如摘要或翻译。
你可能会说:“等等,我可以用ChatGPT或Llama完成所有这些任务。”确实如此——鉴于庞大(且不断增长)的训练数据、运算和训练优化,生成式模型的质量显著提升,并且与几年前相比,零样本能力大幅提升。虽然单解码器模型提供了很好的结果,但目前的共识是,如果有资源,针对特定任务和领域微调模型比使用开箱即用的预训练模型效果更好。例如,如果你想在游戏中实时使用GPT模型生成角色对话,通常情况下,先用类似数据进行微调效果会更好。如果想使用模型从化学论文数据集中提取不同的实体,首先用化学论文微调基于编码器的模型可能更合理。
seq2seq模型的成功在于它们能够将可变长度的输入序列编码为总结输入信息的嵌入。然后模型的解码器部分可以利用这些上下文来进行生成。解码器模型近年来因其简单性、可扩展性、效率和并行化而受到关注。三种类型的模型在业界按照任务广泛使用——没有单一的黄金模型可用于所有任务。
有超过五十万种开源模型,读者可能会想该使用哪一个。第五章将为你拨云见雾,讲解如何为自己的任务和需求选择合适的模型,并介绍如何微调模型以满足自有的特定需求。
局限性
至此,你可能会想知道transformer存在哪些问题。下面简要讨论它的一些局限性:
- transformer非常庞大。研究一致表明,更大的模型表现更好。尽管这很令人兴奋,但也带来了担忧。首先,一些最强大的模型仅训练算力就花费数千万美元——这意味着只有少数机构能够训练非常大的底座模型,限制了没有这些资源的机构的研究。其次,使用如此大量的计算能力也可能带来生态影响——这数百万GPU小时需要耗费大量的电力。第三,即便一些模型是开源的,运行它们可能需要很多GPU(比如马斯克开源的Grok据计算需要8张H100才能运行起来)。第五章将探讨一些在没有多GPU的情况下使用这些大语言模型的技术。即便如此,在资源受限的环境中部署它们仍然是一个常见的挑战。
- 顺序处理:在解码器小节讲到,我们必须为每个新标记处理所有先前的标记。这意味着在一个序列中生成第10000个token将比生成初始标记花费更长的时间。在计算机科学术语中,transformer的时间复杂度与输入长度成二次方关系。即随着输入长度的增加,处理所需的时间成平方增长,使得在非常长的文档中扩展或在某些实时场景中使用这些模型变得具有挑战性。虽然transformer在许多任务中表现出色,但其算力需求在生产中使用时需要仔细考虑和优化。话虽如此,已经有很多研究致力于使transformer在处理超长序列时更高效。
- 固定输入大小:transformer模型可以处理的最大标记数量取决于基础模型。一些模型只能处理512个token,而新技术可以扩展到数十万个标记。模型可以处理的标记数量称为上下文窗口。在选择预训练模型时,这是一个需要注意的重要事项。不能简单地将整本书传递给transformer,就期待其能够总结整书。
- 有限的可解释性:transformer经常因缺乏可解释性而受到批评。
以上都是非常活跃的研究领域——人们一直在探索如何用更少的算力训练和运行模型(例如,第五章将探讨的QLoRA),如何加快生成速度(例如闪存注意力和辅助生成),如何实现不受限制的输入大小(例如RoPE和注意力下沉),以及如何解释注意力机制。
一个需要深入探讨的重要问题是模型中的偏见。如果用于预训练transformer的训练数据包含偏见,模型可能会学习并延续这些偏见。这是机器学习中的广泛存在的问题,但也与transformer有关。我们再来看fill-mask管道。假设想预测最可能的职业。可以看到,使用“man”和“woman”的结果会非常不同。
|
1 2 3 4 5 6 |
unmasker = pipeline("fill-mask", model="bert-base-uncased") result = unmasker("This man works as a [MASK] during summer.") print([r["token_str"] for r in result]) result = unmasker("This woman works as a [MASK] during summer.") print([r["token_str"] for r in result]) |
|
1 2 |
['farmer', 'carpenter', 'gardener', 'fisherman', 'miner'] ['maid', 'nurse', 'servant', 'waitress', 'cook'] |
为什么会这样呢?为了进行预训练,研究人员通常需要大量的数据,这导致他们会爬取所有能找到的内容。这些内容可能质量参差不齐,包括一些不良内容(这些内容在一定程度上可以被过滤掉)。基础模型在微调时可能会保留并延续这些偏见。对话模型中也存在类似的担忧,最终模型可能会生成从预训练数据集中学到的不良内容。
文本之外
Transformer已经被用于许多将数据表示为文本的任务。一个明显的例子是代码生成——我们可以使用大量代码数据来训练语言模型,而不是用通用数据,根据刚刚学到的原理,它将学会如何自动补全代码。另一个例子是使用transformer回答表格中的问题,例如电子表格。
由于transformer模型在文本领域取得了巨大成功,其他领域的社区对将这一技术应用于其他模态产生了浓厚的兴趣。这使得transformer模型被用于图像识别、图像切割、目标检测、视频理解等任务。
卷积神经网络(CNN)一直被广泛用作大多数计算机视觉技术的最新标准模型。随着视觉Transformer(ViT)的引入,近年来人们开始探索如何用注意力和基于transformer的技术处理视觉任务。ViT并没有完全弃用CNN:在图像处理管道中,CNN提取图像的特征图,以检测上层的边缘、纹理和其他模式。然后将从CNN获得的特征图分割成固定大小、不重叠的区块。这些区块可类似于标记序列进行处理,因此注意力机制可以学习不同位置区块之间的关系。
可惜,ViT需要比CNN更多的数据(3亿张图像!)和算力才能取得好的结果。近年来在这方面进行了更多研究,例如DeiT能够利用中型数据集(120万张图像)使用transformer模型,这要归功于使用了CNN中常见的增强和正则化技术。DeiT还使用了一种蒸馏方法,涉及一个“teacher”模型(这里为CNN)。其他模型如DETR、SegFormer和Swin Transformer推动了该领域的发展,支持了许多任务,如图像分类、目标检测、图像切割、视频分类、文档理解、图像修复、超分辨率等。
我们在第9章会学到,transformer模型也可以用于音频任务,如转录音频或生成合成语音或音乐。在底层,预训练和注意力机制的基本原理仍然一致,但每种模态有不同的数据类型,需要不同的方式和调整。
transformer正在探索的其他模态包括:
- 图像:很好的入门读物是Fourrier在2023年出版的《图像机器学习入门》。使用transformer处理图像数据仍然处于非常探索性的阶段,但已有一些令人兴奋的早期结果。涉及图像数据的任务有预测分子的毒性、预测系统的演变或生成新的分子。
- 3D数据:例如,对可以用3D表示的数据进行分割,如自动驾驶中的激光雷达点云或CT扫描中的器官识别。另一个例子是预估物体的六自由度位置,这在机器人应用中非常有用。
- 时间序列:分析股票价格或进行天气预报。
- 多模态:一些transformer模型设计用于同时处理或输出多种类型的数据(如文本、图像和音频)。这打开了新的可能性,例如多模态系统,你可以说话、写作或提供图片,并由一个模型来处理它们。还有视觉问答,其中模型可以回答关于提供图像的问题。
动手时间:使用语言模型生成文本
我们在生成一节使用了generate()方法来执行不同的解码技术。为更好地理解它的内部工作原理,下面我们来自己实现。我们将以generate()方法为参考,但从头开始实现它。我们还将探讨使用generate()方法执行不同的解码技术。
目标是填充以下函数中的代码。我们不使用gpt2.generate(),而是迭代调用gpt2(),传递前面的标记作为输入。你需要实现do_sample=True时的贪心搜索,do_sample=True的采样,以及当do_sample=True且top_k不为None时的Top-K采样。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
def generate( model, tokenizer, input_ids, max_length=50, do_sample=False, top_k=None ): """Generate a sequence without using model.generate() Args: model: The model to use for generation. tokenizer: The tokenizer to use for generation. input_ids: The input IDs max_length: The maximum length of the sequence. Defaults to 50. do_sample: Whether to use sampling. Defaults to False. top_k: The number of tokens to sample from. Defaults to 0. """ # Write your code here # Begin by the simplest approach, greedy decoding. # Then add sampling and finally top-k sampling. |
小结
恭喜!现在你已经学会了加载和使用transformer来完成各种任务!还了解了transformer如何对序列数据(如文本)进行建模,以及这种特性如何让它们“学习”到有用的表示,从而可以用来生成或分类新序列。随着这些模型规模的增加,它们的能力也随之增强——目前拥有数千亿参数的超大模型可以执行许多以前被认为计算机无法完成的任务。
通过微调,我们可以选择现有的强大预训练模型,并修改它们以适应特定领域和用例。向着更大、更强模型的发展趋势已经改变了人们使用这些模型的方式。特定任务的模型经常被通用的LLM超越,大多数人现在通过API和托管解决方案或直接通过流畅的聊天界面与这些模型进行交互。同时,得益于大规模的强大开放访问模型的发布,如Llama,研究人员和从业者的生态系统中涌现出一种浪潮,旨在在用户的计算机上直接运行高质量模型,从而实现隐私优先的解决方案。这一趋势不仅限于推理:近年来,新的训练方法使个人可以在没有大量计算资源的情况下微调这些模型。第五章将深入探讨传统和新式的微调技术。
尽管我们讨论了transformer的工作原理,并且还将深入探讨它们的训练过程,但深入了解这些模型的内部机制(例如注意力机制背后的数学原理)或从头开始预训练模型不在本系列文章的讨论范围内。所幸有许多优秀的资源可以学习这些内容:
- Jay Alammar 的《The Illustrated Transformer》是一份美观的视觉指南,以详细且直观的方式讲解了transformer。
- 如果读者想深入了解微调这些模型以处理不同特定任务的内部机制,我们推荐阅读《Natural Language Processing with Transformers》一书。
- Hugging Face 提供了一门免费、开源的课程,教授如何解决不同的NLP任务。
如果读者希望更深入了解GPT家族的模型,建议你阅读以下论文:
- Improving Language Understanding by Generative Pre-Training:这是2018年由Alec Radford、Karthik Narasimhan、Tim Salimans和Ilya Sutskever发表的原始GPT论文。它提出了使用基于Transformer的模型在大量文本语料库上进行预训练以学习通用语言表示,然后在特定下游任务上进行微调的理念。该论文还显示,GPT模型在当时的几个自然语言理解基准测试中取得了最先进的成果。
- Language Models are Unsupervised Multitask Learners:这篇论文于2019年由Alec Radford、Jeffrey Wu、Rewon Child、David Luan、Dario Amodei和Ilya Sutskever发表。它介绍了GPT-2,一个拥有15亿参数、在一个名为WebText的大型网络文本语料库上预训练的基于Transformer的模型。该论文还展示了GPT-2无需微调即可在各种自然语言任务上表现出色,如文本生成、摘要、翻译、阅读理解和常识推理。最后,它讨论了大规模语言模型的潜在伦理和社会影响。
- Language Models are Few-Shot Learners:这篇论文于2020年由Tom B. Brown等人发表。该论文表明,大幅扩展语言模型可以显著提高它们从少量示例或简单指令中执行新语言任务的能力,无需微调或梯度更新。该论文还介绍了GPT-3,一个拥有1750亿参数的自回归语言模型,在许多NLP数据集和任务上表现出色。
练习
- 注意力机制在文本生成中起什么作用?
- 在什么情况下字符级标记器会更好?
- 如果使用与模型不同的tokenizer会发生什么?
- 在生成时使用
no_repeat_ngram_size有何风险?(提示:城市名称) - 如果结合束集搜索和采样会发生什么?
- 想象你在一个代码编辑器中使用LLM通过采样生成代码。更方便的是低temperature还是高temperature?
- 微调的重要性是什么?为什么它不同于零样本生成?
- 解释编码器、解码器和编码器-解码器transformer的区别及应用。
挑战 - 使用摘要模型(可使用
pipeline(“summarization))生成段落摘要。它与使用零样本生成的结果相比如何?提供少样本示例是否能超越它? - 在零样本补充材料中,我们使用零样本分类计算了混淆矩阵。尝试使用
distilbert-base-uncased-finetuned-sst-2-english编码器模型进行情感分析。得到的结果如何? - 我们来构建一个FAQ系统!Sentence transformers是强大的模型,可以确定多个文本的相似程度。虽然transformer编码器通常为每个标记输出一个嵌入,但句子transformer为整个输入文本输出一个嵌入,使得我们可以根据相似度得分确定两个文本是否相似。我们来看使用sentence_transformers库的简单示例。
|
1 2 3 4 5 6 7 8 9 10 |
from sentence_transformers import SentenceTransformer, util sentences = ["I'm happy", "I'm full of happiness"] model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2") # Compute embedding for both lists embedding_1 = model.encode(sentences[0], convert_to_tensor=True) embedding_2 = model.encode(sentences[1], convert_to_tensor=True) util.pytorch_cos_sim(embedding_1, embedding_2) |
|
1 |
tensor([[0.6003]], device='cuda:0') |
写一个关于某个主题的五个问题和答案的列表。目标是建立一个系统,该系统可以根据新问题给出用户最可能的答案。我们如何使用句子transformer来解决这个问题?补充材料(TODO)中包含了解决方案,尽管具有挑战性,我们建议先尝试自己解决再查看!




